









目標檢測二十年間那些事兒:加速與優化
群卷積
群卷積的目的是通過將特征信道劃分為多個不同的組,然后分別對每個組進行卷積,從而減少卷積層中參數的數量,如上圖(d)所示。如果我們將特征信道平均分成m組,不改變其他構型,理論上卷積的計算復雜度將會降低到原來的1/m。
深度可分離卷積
上圖(e)所示的深度可分離卷積是近年來流行的一種構建輕量級卷積網絡的方法,當組數等于信道數時,可以將它看作是群卷積的一個特例[4]。
假設我們有一個帶有d個濾波器的卷積層和一個 c 通道的特征圖,每個濾波器的大小為 k×k 。對于深度可分卷積,每個 k×k×c 濾波器首先被分割成 c 個片,每個片的大小為 k×k×1 ,然后在每個通道中對濾波器的每個片分別進行卷積。最后,一些 1x1 濾波器用于進行維度轉換,以便最終的輸出應該具有 d 通道。利用深度可分卷積,將計算復雜度從O(dk^2c)降低到O(ck^2)+O(dc)。該思想最近被應用于目標檢測和細粒度分類(Fine-grain classification)。
瓶頸設計
神經網絡中的瓶頸層與前一層相比只包含很少的節點,它可以用來學習降維輸入的高效數據編碼,這在深度自編碼中得到了廣泛的應用。近年來,瓶頸設計被廣泛應用于輕量化網絡的設計[5][6]。在這些方法中,一種常見的方法是壓縮檢測器的輸入層,以減少從檢測管道開始的計算量[5]。另一種方法是壓縮檢測引擎的輸出,使特征圖變薄,使其在后續檢測階段更加高效[6]。
神經結構搜索
近年來,人們對利用神經結構搜索 ( NAS ) 自動設計網絡體系結構而不是依賴于專家經驗和知識產生了濃厚的興趣。NAS 已應用于大規模圖像分類[7],目標檢測[8]和圖像分割任務[9]。NAS 最近在設計輕量級網絡方面也顯示出了很好的結果,其中在搜索過程中考慮了預測精度和計算復雜度的限制[10]。
數值加速技術
我們簡要介紹在目標檢測中經常使用的兩種數值加速技術:1) 頻域加速,2) 降階近似。
頻域加速
卷積是目標檢測中的一種重要的數值運算形式。由于線性檢測器的檢測可以看作是特征圖與檢測器權值之間的窗口內積,因此該過程可以通過卷積來實現。
有很多方法可以加速卷積運算,其中傅里葉變換是一個非常實用的選擇,尤其是對于加速那些大的濾波器。頻域加速卷積的理論基礎是信號處理中的卷積定理,即在合適的條件下,兩個信號卷積的傅里葉變換是其傅里葉空間的點乘:

其中,

是傅里葉變換,

是傅里葉反變換,I和W是輸入圖像和濾波器,*是卷積運算,

是點乘運算。利用快速傅里葉變換 (Fast Fourier Transform,FFT)和快速傅里葉反變換 (Inverse Fast Fourier Transform,IFFT)可以加速上述計算。FFT 和 IFFT 現在經常被用來加速 CNN 模型和一些經典的線性目標檢測器,這使得檢測速度提高了一個數量級。下圖為在頻域中加速線性目標檢測器的標準傳輸途徑(如 HOG 和 DPM)。

降階近似
在深度網絡中,全連接層的計算本質上是兩個矩陣的乘法。當參數矩陣

較大時,檢測器的計算量較大。例如在Fast RCNN檢測器中,將近一半的前向傳遞時間用于計算全連接層。降秩近似是一種加速矩陣乘法的方法。它的目的是對矩陣W進行低秩分解:

其中U是由W的前t列左奇異向量構成的

型矩陣,
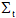
是一個包含W前t個奇異值的

對角矩陣,V是由W的前t行右奇異向量構成的

矩陣。上述過程也稱為截斷 SVD(Truncated SVD),將參數從
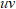
減少到

個,當t遠小于

時效果顯著。截斷 SVD 可以2倍的效率加速 Fast RCNN 檢測器。

 分享
分享
請輸入評論內容...
請輸入評論/評論長度6~500個字









最新活動更多

先進LED照明系統,引領未來趨勢新標桿")


- 1 AI狂歡遇上油價破百,全球股市還能漲多久? | 產聯看全球
- 2 OpenAI深夜王炸!ChatGPT Images 2.0實測:中文穩、細節炸,設計師慌了
- 3 6000億美元估值錨定:字節跳動的“去單一化”突圍與估值重構
- 4 Tesla AI5芯片最新進展總結
- 5 連夜測了一波DeepSeek-V4,我發現它可能只剩“審美”這個短板了
- 6 熱點丨AI“瑜亮之爭”:既生OpenClaw,何生Hermes?
- 7 AI界的殺豬盤:9秒刪庫跑路,全員被封號,還繼續扣錢!
- 8 2026,人形機器人只贏了面子
- 9 DeepSeek降價90%:價格屠夫不是身份,是戰略
- 10 AI Infra產業鏈卡在哪里了?


