









極鏈科技HPAIC人類蛋白質圖譜分類挑戰賽金牌經驗分享
近期,由Kaggle主辦,Leica Microsystems和NVIDIA贊助的HPAIC(Human Protein Atlas Image Classification)競賽正式結束。比賽為期三個月,共有來自全球的2236個隊伍參加,極鏈AI研究院與工程院最終獲得挑戰賽金牌。
比賽介紹
蛋白質是人體細胞中的“行動者”,執行許多共同促進生命的功能。蛋白質的分類僅限于一種或幾種細胞類型中的單一模式,但是為了完全理解人類細胞的復雜性,模型必須在一系列不同的人類細胞中對混合模式進行分類。
可視化細胞中蛋白質的圖像通常用于生物醫學研究,這些細胞可以成為下一個醫學突破的關鍵。然而,由于高通量顯微鏡的進步,這些圖像的生成速度遠遠超過人工評估的速度。因此,對于自動化生物醫學圖像分析以加速對人類細胞和疾病的理解,需要比以往更大的需求。
雖然這是生物學方面的競賽,但是其本質是機器視覺方向的圖像多標簽分類問題,參賽隊伍也包括許多機器視覺和機器學習領域的競賽專家。
數據分析
官方給我們提供了兩種類型的數據集,一部分是512x512的png圖像,一部分是2048x2048或3072x3072的TIFF圖像,數據集大概 268G, 其中訓練集:31072 x 4張,測試集:11702 x 4張。
一個蛋白質圖譜由4種染色方式組成(red,green,blue,yellow),圖像示例如下:
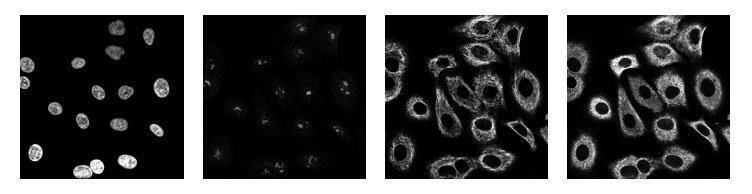
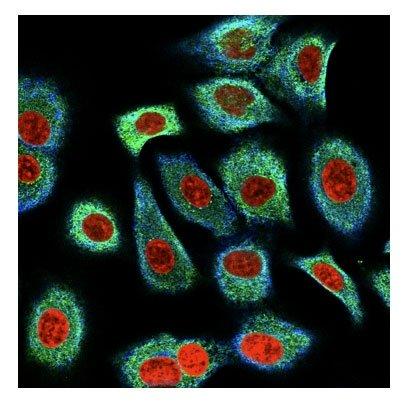
我們將4個通道合并成3通道(RYB)可視化的圖像如下所示:
在本次競賽中一共有28個類別,比如 Nucleoplasm、Nuclear membrane等,每個圖譜圖像都可以有一個或者多個標簽。標簽數量統計如下:

可以發現標簽數量集中在1-3個,但是仍然會有圖像有5個標簽,給比賽增加了一定的難度。
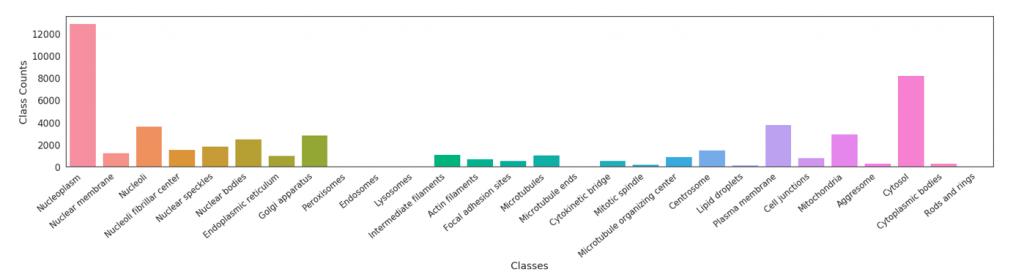
另一方面的難點是數據集中樣本數量很不均勻,圖像最多的類別有12885張,而圖像最少的類別只有11張圖像,這給競賽造成很大的困難,樣本數量分布情況可以在圖中看出。
在比賽過程中逐步有參賽者發現官方的額外數據集HPAv18,并得到官方授權,這些數據集有105678張,很大程度的擴大了樣本數量,同時給我們提供了很大的幫助。
環境資源
硬件方面我們使用了4塊NVIDIA TESLA P100顯卡,使用pytorch作為我們的模型訓練框架。
圖像預處理
HPAv18 圖像與官方給出的圖像有一定的差別,雖然也是由4中染色方式組成,但是每個染色圖像是一個RGB圖像,而不是官方的單通道圖像,而且RGB三個通道的值差別較大,我們對這些圖像做了預處理,對每個RGB圖像只取一個通道(r_out=r,g_out=g,b_out=b,y_out=b),并將這些圖像縮放到512x512和1024x1024兩種尺度。
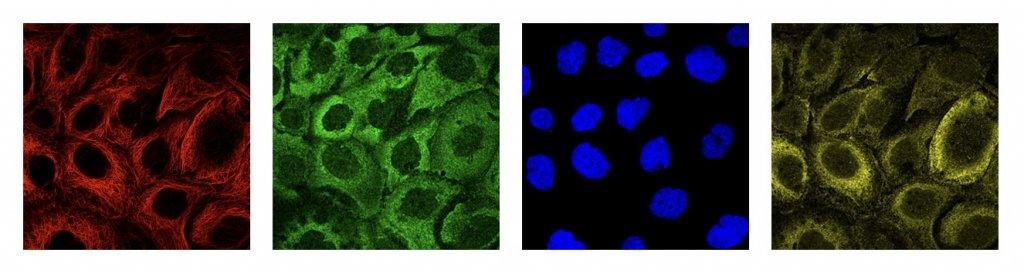
對于TIFF文件,我們用了一周的時間把這個數據集下載下來,然后將所有圖像縮放到1024x1024。
數據增廣
我們比賽中使用的增廣方式有Rotation, Flip 和 Shear三種;因為我們不知道一張圖像中的多個細胞之間是否有關聯關系,所以比賽中沒有使用隨機裁剪的增廣方式。

 分享
分享
請輸入評論內容...
請輸入評論/評論長度6~500個字









最新活動更多

先進LED照明系統,引領未來趨勢新標桿")


- 1 AI狂歡遇上油價破百,全球股市還能漲多久? | 產聯看全球
- 2 OpenAI深夜王炸!ChatGPT Images 2.0實測:中文穩、細節炸,設計師慌了
- 3 6000億美元估值錨定:字節跳動的“去單一化”突圍與估值重構
- 4 Tesla AI5芯片最新進展總結
- 5 連夜測了一波DeepSeek-V4,我發現它可能只剩“審美”這個短板了
- 6 熱點丨AI“瑜亮之爭”:既生OpenClaw,何生Hermes?
- 7 AI界的殺豬盤:9秒刪庫跑路,全員被封號,還繼續扣錢!
- 8 2026,人形機器人只贏了面子
- 9 DeepSeek降價90%:價格屠夫不是身份,是戰略
- 10 AI Infra產業鏈卡在哪里了?


